




A beginner’s tutorial on the apriori algorithm in data mining with R implementation

Introduction
Short stories or tales always help us in understanding a concept better but this is a true story, Wal-Mart’s beer diaper parable. A sales person from Wal-Mart tried to increase the sales of the store by bundling the products together and giving discounts on them. He bundled bread and jam which made it easy for a customer to find them together. Furthermore, customers could buy them together because of the discount.
To find some more opportunities and more such products that can be tied together, the sales guy analyzed all sales records. What he found was intriguing. Many customers who purchased diapers also bought beers. The two products are obviouslyunrelated, so he decided to dig deeper. He found that raising kids is grueling. And to relieve stress, parents imprudently decided to buy beer. He paired diapers with beers and the sales escalated. This is a perfect example of Association Rules in data mining.
This article takes you through a beginner’s level explanation of Apriori algorithm in data mining. We will also look at the definition of association rules. Toward the end, we will look at the pros and cons of the Apriori algorithm along with its R implementation.
Let’s begin byunderstanding what Apriori algorithm is and why is it important tolearn it.
Apriori Algorithm
With the quick growth in e-commerce applications, there is an accumulation vast quantity of data in months not in years. Data Mining, also known as Knowledge Discovery in Databases(KDD), to find anomalies, correlations, patterns, and trends to predict outcomes.
Apriori algorithm is a classical algorithm in data mining. It is used for mining frequent itemsets and relevant associationrules. It is devised to operate on a database containing a lot of transactions, for instance, items brought by customers in a store.
It is very important for effective Market Basket Analysis and it helps the customers in purchasing their items with more ease which increases the sales of the markets. It has also been used in the field of healthcare for the detection of adverse drug reactions. It produces association rules that indicates what all combinations of medications and patient characteristics lead to ADRs. Another application area for data mining is web scraping, where valuable data is extracted from various website. For instance, one could learn the scripting language C# to collect data from web. There are numerous tutorials and guides available such as a guide to C# web scraping for anyone who wishes to gain proficiency in this area.

Association rules
Association rule learning is a prominent and a well-explored method for determining relations among variables in large databases. Let us take a look at the formal definition of the problem of association rules given by Rakesh Agrawal, the President and Founder of the Data Insights Laboratories.
Let I=\{i_1, i_2, i_3, …, i_n\} be a set of n attributes called items and D=\{t_1, t_2, …, t_n\} be the set of transactions. It is called database. Every transaction, t_i in D has a unique transaction ID, and it consists of a subset of itemsets in I.
A rule can be defined as an implication, X\longrightarrow Y where X and Y are subsets of I (X, Y \subseteq I), and they have no element in common, i.e., X\cap Y. X and Y are the antecedent and the consequent of the rule, respectively.
Let’s take an easy example from the supermarket sphere. The example that we are considering is quite small and in practical situations, datasets contain millions or billions of transactions. The set of itemsets, I ={Onion, Burger, Potato, Milk, Beer} and a database consisting of six transactions. Each transaction is a tuple of 0’s and 1’s where 0 represents the absence of an item and 1 the presence.
An example for a rule in this scenario would be {Onion, Potato} => {Burger}, which means that if onion and potato are bought, customers also buy a burger.
| Transaction ID | Onion | Potato | Burger | Milk | Beer |
| t_1 | 1 | 1 | 1 | 0 | 0 |
| t_2 | 0 | 1 | 1 | 1 | 0 |
| t_3 | 0 | 0 | 0 | 1 | 1 |
| t_4 | 1 | 1 | 0 | 1 | 0 |
| t_5 | 1 | 1 | 1 | 0 | 1 |
| t_6 | 1 | 1 | 1 | 1 | 1 |
There are multiple rules possible even from a very small database, so in order to select the interesting ones, we use constraints on various measures of interest and significance. We will look at some of these useful measures such as support, confidence, lift and conviction.
Support
The support of an itemset X, supp(X) is the proportion of transaction in the database in which the item X appears. It signifies the popularity of an itemset.
\displaystyle supp(X) = \frac{\mbox{Number of transaction in which} X \mbox{appears}}{\mbox{Total number of transactions}}.
In the example above, \displaystyle supp(Onion)=\frac{4}{6}=0.66667.
If the sales of a particular product (item) above a certain proportion have a meaningful effect on profits, that proportion can be considered as the support threshold. Furthermore, we can identify itemsets that havesupport values beyond this threshold as significant itemsets.
Confidence
Confidence of a rule is defined as follows:
\displaystyle conf(X\longrightarrow Y)= \frac{supp(X\cup Y)}{supp(X)}
It signifies the likelihood of item Y being purchased when item X is purchased. So, for the rule {Onion, Potato} => {Burger},
\displaystyle conf(\{Onion, Potato\} \implies \{Burger\})= \frac{supp(\{Onion, Potato, Burger\})}{supp(\{Onion, Potato\})}=\frac{3}{6}*\frac{6}{4}=0.75
This implies that for 75% of the transactions containing onion and potatoes, the rule is correct. It can also be interpreted as the conditional probability P(Y|X), i.e, the probability of finding the itemset Y in transactions given the transaction already contains X.
It can give some important insights, but it also has a major drawback. It only takes into account the popularity of the itemset X and not the popularity of Y. If Y is equally popular as X then there will be a higher probability that a transaction containing X will also contain Y thus increasing the confidence. To overcome this drawback there is another measure called lift.
Lift
The lift of a rule is defined as:
\displaystyle lift(X\longrightarrow Y)=\frac{supp(X\cup Y)}{supp(X)*supp(Y)}
This signifies the likelihood of the itemset Ybeing purchased when item X is purchased while taking into account the popularity of Y.
In our example above,
\displaystyle lift(\{Onion, Potato\}\implies \{Burger\})= \frac{supp(\{Onion, Potato, Burger\})}{supp(\{Onion, Potato\})*supp(Burger)}=\frac{3}{6}*\frac{6*6}{4*4}=1.125
If the value of lift is greater than 1, it means that the itemset Y is likely to be bought with itemset X, while a value less than 1 implies that itemset Y is unlikely to be bought if the itemset X is bought.
Conviction
The conviction of a rule can be defined as:
\displaystyle conv(X\longrightarrow Y)=\frac{1-supp(Y)}{1-conf(X\longrightarrow Y)}
For the rule {onion, potato}=>{burger}
\displaystyle conv(\{onion, potato\}\implies \{burger\}) = \frac{1-supp(burger)}{1- conf(\{onion,potato\}\implies \{burger\})} = \frac{1-0.67}{1-0.75} = 1.32
The conviction value of 1.32 means that the rule {onion,potato}=>{burger} would be incorrect 32% more often if the association between X and Y was an accidental chance.
How does Apriori algorithm work?
So far, we learned what the Apriori algorithm is and why is important to learn it.
A key concept in Apriori algorithm is the anti-monotonicity of the support measure. It assumesthat
- All subsets of a frequent itemset must be frequent
- Similarly, for any infrequent itemset, all its supersets must be infrequent too
Let us now look at the intuitive explanation of the algorithm with the help of the example we usedabove. Before beginning the process, let us set the support threshold to 50%, i.e. only those items are significant for which support is more than 50%.
Step 1: Create a frequency table of all the items that occur in all the transactions. For our case:
| Item | Frequency (No. of transactions) |
| Onion(O) | 4 |
| Potato(P) | 5 |
| Burger(B) | 4 |
| Milk(M) | 4 |
| Beer(Be) | 2 |
Step 2: We know that only those elements are significant for which the support is greater than or equal to the threshold support. Here, support threshold is 50%, hence only those items are significant which occur in more than threetransactions and such items are Onion(O), Potato(P), Burger(B), and Milk(M). Therefore, we are left with:
| Item | Frequency (No. of transactions) |
| Onion(O) | 4 |
| Potato(P) | 5 |
| Burger(B) | 4 |
| Milk(M) | 4 |
The table above represents the single items that are purchased by the customers frequently.
Step 3: The next step is to make all the possible pairs of the significant items keeping in mind that the order doesn’t matter, i.e., AB is same as BA. To do this, take the first item and pair it with all the others such as OP, OB, OM. Similarly, consider the second item and pair it with preceding items, i.e., PB, PM. We are only considering the preceding items because PO (same as OP) already exists. So, all the pairs in our example are OP, OB, OM, PB, PM, BM.
Step 4: We will now count the occurrences of each pair in all the transactions.
| Itemset | Frequency (No. of transactions) |
| OP | 4 |
| OB | 3 |
| OM | 2 |
| PB | 4 |
| PM | 3 |
| BM | 2 |
Step 5: Again only those itemsets are significant which cross the support threshold, and those are OP, OB, PB, and PM.
Step 6: Now let’s say we would like to look for a set of three items that are purchased together. We will use the itemsets found in step 5 and create a set of 3 items.
To create a set of 3 items another rule, called self-join is required. It says that from the item pairs OP, OB, PB and PM we look for two pairs with the identical first letterand so we get
- OP and OB, this gives OPB
- PB and PM, this gives PBM
Next, we find the frequency for these two itemsets.
| Itemset | Frequency (No. of transactions) |
| OPB | 4 |
| PBM | 3 |
Applying the threshold rule again, we find that OPB is the only significant itemset.
Therefore, the set of 3 items that was purchased most frequently is OPB.
The example that we considered was a fairly simple one and mining the frequent itemsets stopped at 3 items but in practice, there are dozens of items and this process could continue to many items. Suppose we got the significant sets with 3 items as OPQ, OPR, OQR, OQS and PQR and now we want to generate the set of 4 items. For this, we will look at the sets which have first two alphabets common, i.e,
- OPQ and OPR gives OPQR
- OQR and OQS gives OQRS
In general, we have to look for sets which only differ in their last letter/item.
Now that we have looked at an example of the functionality of Apriori Algorithm, let us formulate the general process.
General Process of the Apriori algorithm
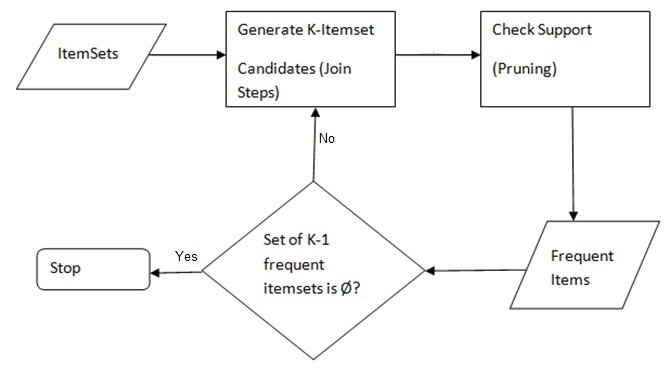
The entire algorithm can be divided into two steps:
Step 1: Apply minimum support to find all the frequent sets with k items in a database.
Step 2: Use the self-join rule to find the frequent sets with k+1 items with the help of frequent k-itemsets. Repeat this process from k=1 to the point when we are unable to apply the self-join rule.
This approach of extending a frequent itemset one at a time is called the “bottom up” approach.
Mining Association Rules
Till now, we have looked at the Apriori algorithm with respect to frequent itemset generation. There is another task for which we can use this algorithm, i.e., finding association rules efficiently.
For finding association rules, we need to find all rules having support greater than the threshold support and confidence greater than the threshold confidence.
But, how do we find these? One possible way is brute force, i.e., to list all the possible association rules and calculate the support and confidence for each rule. Then eliminate the rules that fail the threshold support and confidence. But it is computationally very heavy and prohibitive as the number of all the possible association rules increase exponentially with the number of items.
Given there are n items in the set I, the total number of possible association rules is 3^n – 2^{n+1} + 1.
We can also use another way, which is called the two-step approach, to find the efficient association rules.
The two-step approach is:
Step 1: Frequent itemset generation: Find all itemsets for which the support is greater than the threshold support following the process we have already seen earlier in this article.
Step 2: Rule generation: Create rules from each frequent itemset using thebinary partition of frequent itemsets and look for the ones with high confidence. These rules are called candidate rules.
Let us look at our previous example to get an efficient association rule. We found that OPB was the frequent itemset. So for this problem,step 1 is already done. So, let’ see step 2. All the possible rules using OPB are:
OP\longrightarrowB, OB\longrightarrowP, PB\longrightarrowO, B\longrightarrow OP, P\longrightarrowOB, O\longrightarrowPB
If X is a frequent itemset with k elements, then there are 2^k-2 candidate association rules.
We will not go deeperinto the theory of the Apriori algorithm for rule generation.
Pros of the Apriori algorithm
- It is an easy-to-implement and easy-to-understand algorithm.
- It can be used on large itemsets.
Cons of the Apriori Algorithm
- Sometimes, it may need to find a large number of candidate rules which can be computationally expensive.
- Calculating support is also expensive because it has to go through the entire database.
R implementation
The package which is used to implement the Apriori algorithm in R is calledarules. The function that we will demonstrate here which can be used for mining association rules is
apriori(data, parameter = NULL)
The arguments of the function apriori are
data: The data structure which can be coerced into transactions (e.g., a binary matrix or data.frame).
parameter: It is a named list containing the threshold values for support and confidence. The default value of this argument is a list of minimum support of 0.1, minimum confidence of 0.8, maximum of 10 items (maxlen), and a maximal time for subset checking of 5 seconds (maxtime).
https://gist.github.com/HackerEarthBlog/98dca27a7e48694506db6ae413d7570e
Summary
Through this article, we have seen how data mining is helping us make decisions that are advantageousfor both customers and industries. We have also seen a simple explanation of the Apriori algorithm, along with its implementation in R. It is not only used by the retail industry to provide us the discount on some bundles of products. The use cases of the Apriori algorithm stretchto Google’s auto-completion features and Amazon’s recommendation systems.
This tutorial aims tomake the reader familiar with the fundamentals of the Apriori algorithm and a general process followed to mine frequent itemsets. Hope you are familiar now!
- How to hire a data scientist
- 5 must-have proctoring tips for a developer assessment platform
- How to ensure your tech talent pool is poaching proof
Get advanced recruiting insights delivered every month
Hire top tech talent with our recruitment platform
Access Free DemoGet advanced recruiting insights delivered every month
Get insightful articles from the world of tech recruiting straight to your inbox
Related reads

Vibe Coding: Shaping the Future of Software
A New Era of Code Vibe coding is a new method of using natural language prompts and AI tools to generate code. I…

Guide to Conducting Successful System Design Interviews in 2025
Article Summary Introduction to Systems Design Common System Design interview questions The difference between a System Design interview and a coding interview Best…

How Candidates Use Technology to Cheat in Online Technical Assessments
Article Summary How online assessments have transformed hiring Current state of cheating in online technical assessments Popular techniques candidates use to cheat Steps…

Talent Acquisition Strategies For Rehiring Former Employees
Former employees who return to work with the same organisation are essential assets. In talent acquisition, such employees are also termed as ‘Boomerang…

Automation in Talent Acquisition: A Comprehensive Guide
Automation has become a major element in the modern-day hiring process. The automated hiring process gained momentum since the advent of remote work…

Predictive Analytics for Talent Management
The job landscape in today’s age is highly competitive for both job seekers and hiring managers. Finding the right talent under such conditions…



