




Continuous Deployment System

This is one of the coolest and most important things we recently built at HackerEarth.
What’s so cool about it? Just have a little patience, you will soon find out. But make sure you read till the end 🙂
I hope to provide valuable insights into the implementation of a Continuous Deployment System(CDS).
At HackerEarth, we iterate over our product quickly and roll out new features as soon as they are production ready. In the last two weeks, we deployed 100+ commits in production, and a major release comprising over 150+ commits is scheduled for launch within a few days. Those commits consist of changes to backend app, website, static files, database, and so on. We have over a dozen different types of servers running, for example, webserver, code-checker server, log server, wiki server, realtime server, NoSQL server, etc. All of them are running on multiple EC2 instances at any point in time. Our codebase is still tightly integrated as one single project with many different components required for each server. When there are changes to the codebase, you need to update all the related dedicated servers and components when deploying in production. Doing that manually would have just driven us crazy and would have been a total waste of time!
Look at the table of commits deployed on a single day.
And with such speed, we needed an automated deployment system along with automated testing. Our implementation of CDS helped the team roll out features in production with just a single command: git push origin master. Also, another reason to use CDS is that we are trying to automate everything, and I see us going in right direction.
CDS Model
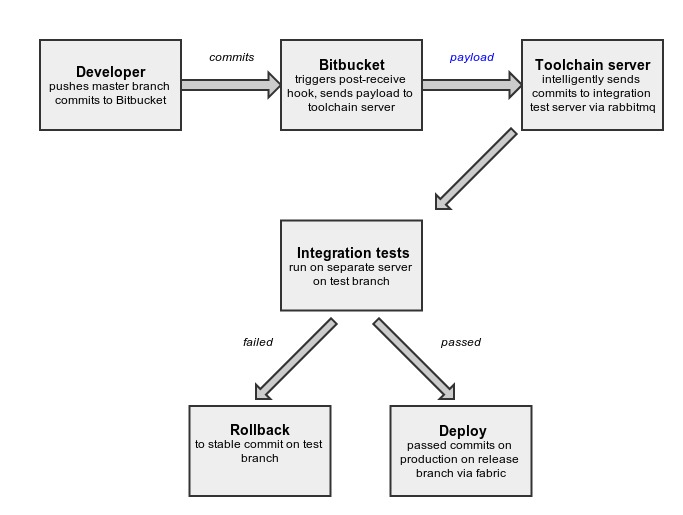
The process begins with the developer pushing a bunch of commits from his master branch to a remote repository, which in our case is set up on Bitbucket. We have set up a post hook on Bitbucket, so as soon as Bitbucket receives commits from the developer, it generates a payload(containing information about commits) and sends it to the toolchain server.
The toolchain server backend receives the payload and filters commits based on the branch and neglects any commit that is not from the master branch or of the type merge commit.
def filter_commits(branch=settings.MASTER_BRANCH, all_commits=[]):
"""
Filter commits by branch
"""
commits = []
# Reverse commits list so that we have branch info in first commit.
all_commits.reverse()
for commit in all_commits:
if commit['branch'] is None:
parents = commit['parents']
# Ignore merge commits for now
if parents.__len__() > 1:
# It's a merge commit and
# We don't know what to do yet!
continue
# Check if we just stored the child commit.
for lcommit in commits:
if commit['node'] in lcommit['parents']:
commit['branch'] = branch
commits.append(commit)
break
elif commit['branch'] == branch:
commits.append(commit)
# Restore commits order
commits.reverse()
return commitsFiltered commits are then grouped intelligently using a file dependency algorithm.
def group_commits(commits):
"""
Creates groups of commits based on file dependency algorithm
"""
# List of groups
# Each group is a list of commits
# In list, commits will be in the order they arrived
groups_of_commits = []
# Visited commits
visited = {}
# Store order of commits in which they arrived
# Will be used later to sort commits inside each group
for i, commit in enumerate(commits):
commit['index'] = i
# Loop over commits
for commit in commits:
queue = deque()
# This may be one of the group in groups_of commits,
# if not empty in the end
commits_group = []
commit_visited = visited.get(commit['raw_node'], None)
if not commit_visited:
queue.append(commit)
while len(queue):
c = queue.popleft()
visited[c['raw_node']] = True
commits_group.append(c)
dependent_commits = get_dependent_commits_of(c, commits)
for dep_commit in dependent_commits:
commit_visited = visited.get(dep_commit['raw_node'], None)
if not commit_visited:
queue.append(dep_commit)
if len(commits_group)>0:
# Remove duplicates
nodes = []
commits_group_new = []
for commit in commits_group:
if commit['node'] not in nodes:
nodes.append(commit['node'])
commits_group_new.append(commit)
commits_group = commits_group_new
# Sort list using index key set earlier
commits_group_sorted = sorted(commits_group, key= lambda
k: k['index'])
groups_of_commits.append(commits_group_sorted)
return groups_of_commitsThe top commit of each group is sent for testing to the integration test server via rabbitmq. First, I wrote code which sent each commit for testing, but it was too slow. So Vivek suggested that I group commits from payload and run a test on the top commit of each group, which drastically reduced number of times tests are run.
Integration tests are run on the integration test server. There is a separate branch called test on which tests are run. Commits are cherry-picked from master onto test branch. Integration test server is a simulated setup to replicate production behavior. If tests are passed, then commits are put in release queue from where they are released in production. Otherwise, the test branch is rolled back to a previous stable commit and clean-up actions are performed, including notifying the developer whose commits failed the tests.
Git Branch Model
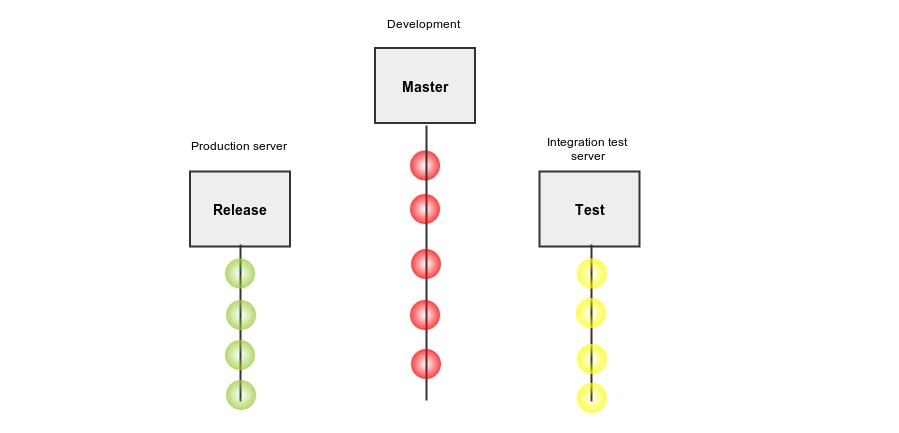
We have been using three branches — master, test, and release. In the Master, the developer pushes the code. This branch can be unstable. Test branch is for the integration test server and release branch is for the production server. Release and test branches move parallel, and they are always stable. As we write more tests, the uncertainty of a bad commit being deployed to production will reduce exponentially.
Django Models
Each commit(or revision) is stored in the database. This data is helpful in many circumstances like finding previously failed commits, relating commits to each other using file dependency algorithm, monitoring deployment, etc.
Following are the Django models used:* Revision– commithash, commitauthor, etc. * Revision Status– revisionid, testpassed, deployedonproduction, etc. * Revision Files– revisionid, filepath * Revision Dependencies.
When the top commit of each group is passed to the integration test server, we first find its dependencies, that is, previously failed commits using the file dependency algorithm, and save it in the Revision Dependencies model so that we can directly query from the database the next time.
def get_dependencies(revision_obj):
dependencies = set()
visited = {}
queue = deque()
filter_id = revision_obj.id
queue.append(revision_obj)
while len(queue):
rev = queue.popleft()
visited[rev.id] = True
dependencies.add(rev)
dependent_revs = get_all_dependent_revs(rev, filter_id)
for rev in dependent_revs:
r_visited = visited.get(rev.id, None)
if not r_visited:
queue.append(rev)
#remove revision from it's own dependecies set.
#makes sense, right?
dependencies.remove(revision_obj)
dependencies = list(dependencies)
dependencies = sorted(dependencies, key=attrgetter('id'))
return dependencies
def get_all_dependent_revs(rev, filter_id):
deps = rev.health_dependency.all()
if len(deps)>0:
return deps
files_in_rev = rev.files.all()
files_in_rev = [f.filepath for f in files_in_rev]
reqd_revisions = Revision.objects.filter(files__filepath__in=files_in_rev, id__lt=filter_id, status__health_status=False)
return reqd_revisions
As we saw earlier in the Overview section, these commits are then cherry-picked onto the test branch from the master branch, and the process continues.
Deploying to Production
Commits that passed integration tests are now ready to be deployed. There are a few things to consider when deploying code to production, such as restarting webserver, deploying static files, running database migrations, etc. The toolchain code intelligently decides which servers to restart, whether to collect static files or run database migrations, and which servers to deploy on based on what changes were done in the commits. You might have noticed we do all this on the basis of types and categories of files changed/modified/deleted in the commits to be released.
You might also have noted that we control deployment to production and test servers from the toolchain server (that’s the one which receives payload from bitbucket). We use fabric to achieve this. A great tool indeed for executing remote administrative tasks!
from fabric.api import run, env, task, execute, parallel, sudo
@task
def deploy_prod(config, **kwargs):
"""
Deploy code on production servers.
"""
revision = kwargs['revision']
commits_to_release = kwargs['commits_to_release']
revisions = []
for commit in commits_to_release:
revisions.append(Revision.objects.get(raw_node=commit))
result = init_deploy_static(revision, revisions=revisions, config=config,
commits_to_release=commits_to_release)
is_restart_required = toolchain.deploy_utils.is_restart_required(revisions)
if result is True:
init_deploy_default(config=config, restart=is_restart_required)
All these processes take about 2 minutes for deployment on all machines for a group of commits or single push. Our life is a lot easier; we don’t worry anymore about pushing our code, and we can see our feature or bug fix or anything else live in production in just a few minutes. Undoubtedly, this will also help us release new features without wasting much time. Now deploying is as simple as writing code and testing on a local machine. We also deployed the hundredth commit to production a few days ago using automated deployment, which stands testimony to the robustness of this system.
P.S. I am an undergraduate student at IIT-Roorkee. You can find me @LalitKhattar.
This post was originally written for the HackerEarth Engineering blog by Lalit Khattar, Summer Intern 2013 @HackerEarth
Get advanced recruiting insights delivered every month
Hire top tech talent with our recruitment platform
Access Free DemoGet advanced recruiting insights delivered every month
Get insightful articles from the world of tech recruiting straight to your inbox
Related reads

Guide to Conducting Successful System Design Interviews in 2025
Article Summary Introduction to Systems Design Common System Design interview questions The difference between a System Design interview and a coding interview Best…

How Candidates Use Technology to Cheat in Online Technical Assessments
Article Summary How online assessments have transformed hiring Current state of cheating in online technical assessments Popular techniques candidates use to cheat Steps…

Talent Acquisition Strategies For Rehiring Former Employees
Former employees who return to work with the same organisation are essential assets. In talent acquisition, such employees are also termed as ‘Boomerang…

Automation in Talent Acquisition: A Comprehensive Guide
Automation has become a major element in the modern-day hiring process. The automated hiring process gained momentum since the advent of remote work…

Predictive Analytics for Talent Management
The job landscape in today’s age is highly competitive for both job seekers and hiring managers. Finding the right talent under such conditions…

How To Create A Positive Virtual Onboarding Experience?
The advent of the pandemic changed the hiring industry in many ways. One of the biggest outcomes of this global phenomenon was that…



