In the previous article, we saw how dplyr and tidyr packages in R can be used to visualize and plot data to gain a better understanding of the underlying properties. Now let’s explore the data visualization techniques in Python and see how similar tasks can be performed.
Pandas:
Pandas is a Python package aimed toward creating a platform to carry out practical data analysis and manipulation tasks. It has data structures that are equivalent to dataframe in R, and it can handle multiple types of data like SQL or Excel data, information present in the form of matrices, time series data, and labeled/unlabeled data. Here’s a preview of the tasks that can be carried out using Pandas:
You can import Pandas just like you would import any other library in Python.
@ import pandas as pd
First step of dealing with Pandas involves reading data from a csv file.
@ data = pd.read_csv(file_path, header)
File_path: the location of the csv file to be read
Header: Can be None if you want the column heading to be Null. If column names are needed, then pass them as a list to the header argument.
After reading the data, placing it into a dataframe gives us the flexibility to perform various operations on it. To convert data into dataframe format use:
@ data_df = pd.DataFrame(data, column_list)
We are going to use the following dataframe in our later examples:
>>> marks_df names marks 0 Ross 90 1 Joey 72 2 Monica 81 3 Phoebe 80 4 Chandler 45 5 Rachel 78
It is always important to have an estimate about the extreme values of the data. It is also convenient to have the data in a sorted format. To accomplish this, data can be sorted based on a column value in the dataframe using the sorting function:
@ df_sort = dataframe.sort_values(column, ascending)
column : column object of the dataframe
ascending: default value is True. If set to False, the data is sorted in descending order.
>>> list_sort = marks_df.sort_values(['marks']) >>> list_sort names marks 4 Chandler 45 1 Joey 72 5 Rachel 78 3 Phoebe 80 2 Monica 81 0 Ross 90
To get the entity with the maximum value (which is the last value in the sorted dataframe), tail(n) function can be used. n is the number of values from the last elements that need to be taken into consideration:
@ df_sort.tail(1) >>> list_sort.tail(1) names marks 0 Ross 90
Similarly, head() collects values from the top:
>>> list_sort.head(2) names marks 4 Chandler 45 1 Joey 72
Both head and tail, by default, will display 5 values from the top and bottom, respectively.
To get the information about the dataframe, use info():
@ marks_df.info() >>> marks_df.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 6 entries, 0 to 5 Data columns (total 2 columns): names 6 non-null object marks 6 non-null int64 dtypes: int64(1), object(1) memory usage: 168.0+ bytes
In the examples that follow, we are going to use the following dataframe that contains the complete exam results of all the 6 students (there are 6 subjects):
>>> allmarks_df
When there are multiple entries for each object, the aggregate option comes into play. We use the groupby() function to accomplish it. To get the total marks for each student, we need to aggregate all the name objects using the sum function:
@ agg_object = dataframe.groupby(column_name, as_index)
column_name: takes the list of columns based on which grouping needs to be done.
as_index: default value is True and means that the columns mentioned in list will be considered as indices for the new dataframe formed. When set to False, numerical numbering starting from 0 is given as the index.
>>> marks_agg = allmarks_df.groupby('Name')
>>> total_df = marks_agg.sum()
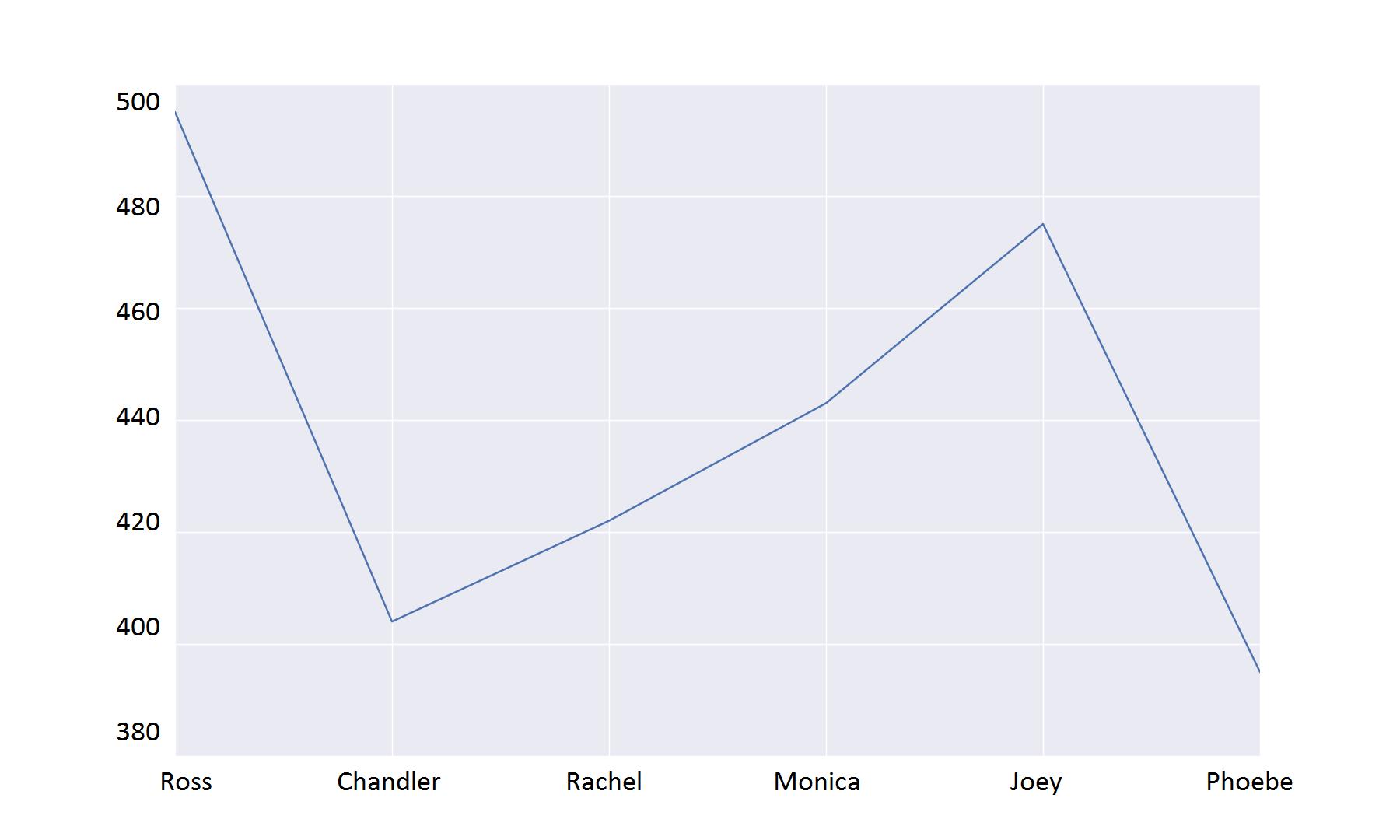
>>> total_df
Name Marks
Ross 495
Chandler 404
Rachel 422
Monica 443
Joey 475
Phoebe 395
>>> total_df = allmarks_df.groupby('Name',as_index= False).sum()
>>> total_df
Name Marks
0 Ross 495
1 Chandler 404
2 Rachel 422
3 Monica 443
4 Joey 475
5 Phoebe 395 Data can also be plotted using Pandas, but it requires pyplot from matplotlib:
>>> import matplotlib.pyplot as plt >>> total_df['Marks'].plot(title="Total marks of all students") <matplotlib.axes.AxesSubplot object at 0x10cde0d10> >>> plt.show()
>>> total_df['Marks'].plot.bar() <matplotlib.axes.AxesSubplot object at 0x10c2d1e90> >>> plt.show()
To get the frequencies of the values in a particular column, use value_counts():
@ dataframe[column_name].value_counts() >>> allmarks_df['Name'].value_counts() Chandler 6 Ross 6 Rachel 6 Phoebe 6 Monica 6 Joey 6 Name: Name, dtype: int64
To get the unique values in a column:
@ dataframe[column_name].unique() >>> allmarks_df['Name'].unique() array(['Ross', 'Joey', 'Monica', 'Phoebe ', 'Chandler', 'Rachel'], dtype=object)
Dataframes can be accessed using the index too. ix() function is used to extract data using the index in numerical values:
@ dataframe.ix(index_range, columns_range) >>> allmarks_df.ix[0:6,:] Name Marks 0 Ross 77 1 Joey 73 2 Monica 80 3 Phoebe 58 4 Chandler 54 5 Rachel 51 6 Ross 98 >>> allmarks_df.ix[0:6,0] 0 Ross 1 Joey 2 Monica 3 Phoebe 4 Chandler 5 Rachel 6 Ross Name: Name, dtype: object >>> allmarks_df.ix[0:6,0:1] Name 0 Ross 1 Joey 2 Monica 3 Phoebe 4 Chandler 5 Rachel 6 Ross
Adding a column to data is quite easy in case of dataframe in Pandas:
@ dataframe[new_column] = value >>> total_df['Pass'] = [total_df['Marks'][i]>=420 for i in range(6)] >>> total_df Name Marks Pass Ross 495 True Chandler 404 False Rachel 422 True Monica 443 True Joey 475 True Phoebe 395 False
loc() can be used to extract subset of a dataframe:
@ dataframe.loc[index / index_range] >>> total_df.loc['Monica'] Marks 443 Pass True Name: Monica, dtype: object >>> total_df.loc['Monica':'Phoebe '] Name Marks Pass Monica 443 True Joey 475 True Phoebe 395 False
iloc() is similar to loc() but here the index can be represented as numerals rather than as actual object names:
Subset of the dataframe can also be extracted by imposing a condition over the column values using logical operators:
>>> total_pass = total_df[total_df['Pass'] == True] >>> total_pass
In the above example, all the rows with ‘Pass’ column value as True are separated out using the logical equality condition.
You can use the del function to delete a column.
@ del dataframe[column_name] >>> del total_df['Pass'] >>> total_df
Data can be changed into different storage formats. stack() and unstack() functions are used for this. stack() is used to bring down the column names into index values and unstack() is used to revert the stacking action. Give it a try and see the output.
@ dataframe.stack() >>> total_df.stack() >>> total_df.unstack()
The rows and columns interchange positions after unstacking. We can revert this using the transpose function.
>>> total_df = total_df.T >>> total_df Name Ross Chandler Rachel Monica Joey Phoebe Marks 495 404 422 443 475 395 Pass True False True True True False >>> total_df = total_df.T >>> total_df Name Marks Pass Ross 495 True Chandler 404 False Rachel 422 True Monica 443 True Joey 475 True Phoebe 395 False
Mean and standard deviation for a particular value of the data can be calculated using standard functions. Mean: mean() and standard deviation: std()
@ dataframe[column_name].mean() @ dataframe[column_name].std() >>> total_df['Marks'].mean() 439.0 >>> total_df['Marks'].std() 39.744181964156716 >>> total_df['dis-Mean'] = total_df['Marks']-total_df['Marks'].mean() >>> total_df Name Marks dis-Mean 0 Ross 495 56.0 1 Chandler 404 -35.0 2 Rachel 422 -17.0 3 Monica 443 4.0 4 Joey 475 36.0 5 Phoebe 395 -44.0
The above example adds a column to the dataframe containing the deviation from the mean value of Marks.
Generating a time series data:
>>> time = pd.date_range('1/1/2012', periods=48, freq='MS')
>>> time
DatetimeIndex(['2012-01-01', '2012-02-01', '2012-03-01', '2012-04-01',
'2012-05-01', '2012-06-01', '2012-07-01', '2012-08-01',
'2012-09-01', '2012-10-01', '2012-11-01', '2012-12-01',
'2013-01-01', '2013-02-01', '2013-03-01', '2013-04-01',
'2013-05-01', '2013-06-01', '2013-07-01', '2013-08-01',
'2013-09-01', '2013-10-01', '2013-11-01', '2013-12-01',
'2014-01-01', '2014-02-01', '2014-03-01', '2014-04-01',
'2014-05-01', '2014-06-01', '2014-07-01', '2014-08-01',
'2014-09-01', '2014-10-01', '2014-11-01', '2014-12-01',
'2015-01-01', '2015-02-01', '2015-03-01', '2015-04-01',
'2015-05-01', '2015-06-01', '2015-07-01', '2015-08-01',
'2015-09-01', '2015-10-01', '2015-11-01', '2015-12-01'],
dtype='datetime64[ns]', freq='MS')
>>> stock = pd.DataFrame([np.random.randint(low=0,high=50) for i in range(48)], index=time, columns=['Value'])
>>> stock['dev'] = stock['Value']-stock['Value'].mean()
>>> stock
Value dev
2012-01-01 37 10.104167
2012-02-01 48 21.104167
2012-03-01 41 14.104167
2012-04-01 5 -21.895833
2012-05-01 13 -13.895833
2012-06-01 7 -19.895833
2012-07-01 37 10.104167
2012-08-01 31 4.104167
2012-09-01 32 5.104167
2012-10-01 46 19.104167
2012-11-01 40 13.104167
2012-12-01 18 -8.895833
2013-01-01 38 11.104167
2013-02-01 23 -3.895833
2013-03-01 17 -9.895833
2013-04-01 21 -5.895833
2013-05-01 12 -14.895833
2013-06-01 40 13.104167
2013-07-01 9 -17.895833
2013-08-01 47 20.104167
2013-09-01 42 15.104167
2013-10-01 3 -23.895833
2013-11-01 24 -2.895833
2013-12-01 38 11.104167
2014-01-01 33 6.104167
2014-02-01 41 14.104167
2014-03-01 25 -1.895833
2014-04-01 11 -15.895833
2014-05-01 44 17.104167
2014-06-01 47 20.104167
2014-07-01 6 -20.895833
2014-08-01 49 22.104167
2014-09-01 11 -15.895833
2014-10-01 14 -12.895833
2014-11-01 23 -3.895833
2014-12-01 35 8.104167
2015-01-01 23 -3.895833
2015-02-01 1 -25.895833
2015-03-01 46 19.104167
2015-04-01 49 22.104167
2015-05-01 16 -10.895833
2015-06-01 25 -1.895833
2015-07-01 22 -4.895833
2015-08-01 36 9.104167
2015-09-01 30 3.104167
2015-10-01 3 -23.895833
2015-11-01 12 -14.895833
2015-12-01 20 -6.895833 Plotting the value of stock over 4 years using pyplot:
stock['Value'].plot() <matplotlib.axes.AxesSubplot object at 0x10a29bb10> >>> plt.show()
>>> stock['dev'].plot.bar() <matplotlib.axes.AxesSubplot object at 0x10c3e09d0> >>> plt.show()
There are more plotting tools like the seaborn library that can create more sophisticated plots. With these data visualization packages in R and Python, we are ready to advance to the core concepts of Machine Learning.
We have our Machine Learning practice section coming soon. Stay tuned.
A New Era of Code Vibe coding is a new method of using natural language…
Article Summary Introduction to Systems Design Common System Design interview questions The difference between a…
Article Summary How online assessments have transformed hiring Current state of cheating in online technical…
Former employees who return to work with the same organisation are essential assets. In talent…
Automation has become a major element in the modern-day hiring process. The automated hiring process…
The job landscape in today’s age is highly competitive for both job seekers and hiring…